Our First Module
Let's create our first module and learn step-by-step how to build it.
Step 1: Creating an Empty Module, module.py

Working locally on your machine, start from scratch by creating an empty file named module.py for the first part of the experiment. This file will serve as the module, and even though it's empty now, you will soon fill it with actual code. The straightforward name, module.py, is chosen for simplicity and clarity.
Step 2: Importing module.py
Then, create second file named as main.py in the same folder contains the code module.py that uses the new module (import module). To get started, it's best to create an empty new folder and place both files in it.
Next, open IDLE or your preferred IDE, and run the main.py file. If everything is set up correctly, you won't see any output, which means Python has successfully imported the contents of the module.py file, even if it's currently empty.
Now, take a look at the folder where both files are located. You'll notice a new subfolder named pycache. Go inside this folder, and you'll find a file named something like module.cpython-xy.pyc, where x and y correspond to your Python version (e.g., 3 and 8 for Python 3.8).
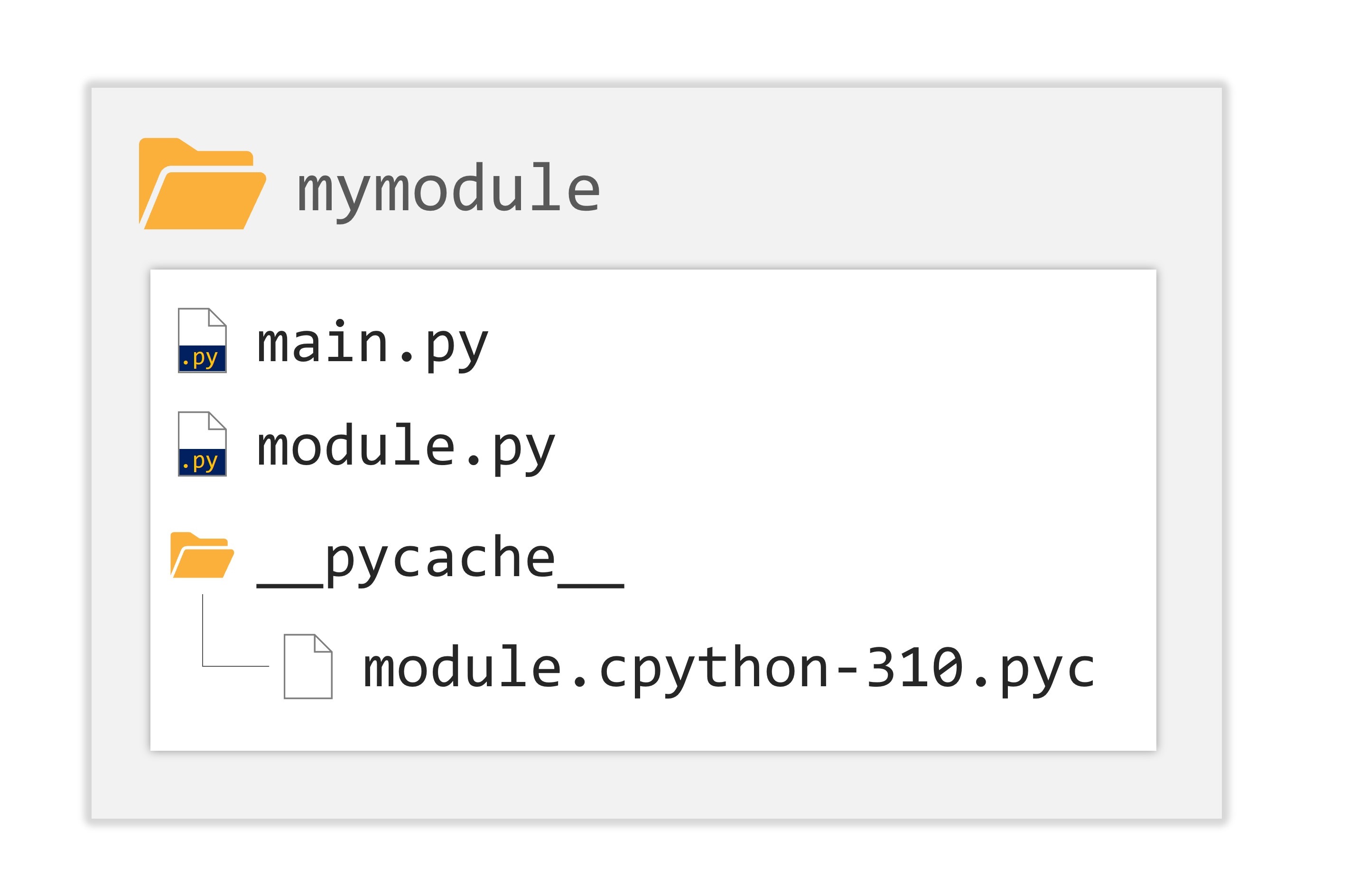
The name of this file matches the name of your module (module in this case). The part after the first dot indicates the Python implementation that created the file (CPython in this case) and its version number. The last part, .pyc, comes from "Python" and "compiled".
You can't read the contents of this file directly because it's in a semi-compiled form intended for Python's internal use. When Python imports a module for the first time, it translates its contents into this semi-compiled shape.
This semi-compiled file doesn't contain machine code but is optimized for Python's interpreter, leading to faster execution compared to interpreting the source text from scratch. It also doesn't require as many checks as a pure source file, further contributing to its faster performance.
The Python interpreter automatically handles the process of checking if the module's source file has been modified. If it has, the .pyc file will be rebuilt; otherwise, the existing .pyc file may be used directly. This entire process is automatic and transparent to the user, so you don't need to worry about it.
Step 3: Running module.py
Now, let's type in the following code in module.py and save it:
print("**Module Function**")If you run module.py, and you will see the following output:
Step 4: Running main.py
Then, go back to main.py file, and run main.py. You should see the same output as in Step 3.
But what does this output mean?
When a module is imported in Python, its contents are automatically executed. This gives the module an opportunity to initialize certain internal aspects, like assigning variables with useful values.
It's essential to note that the initialization happens only once, during the first import. So, if a module is imported multiple times, Python remembers the imported modules and skips redundant imports silently.
Example
For example, in the given context:
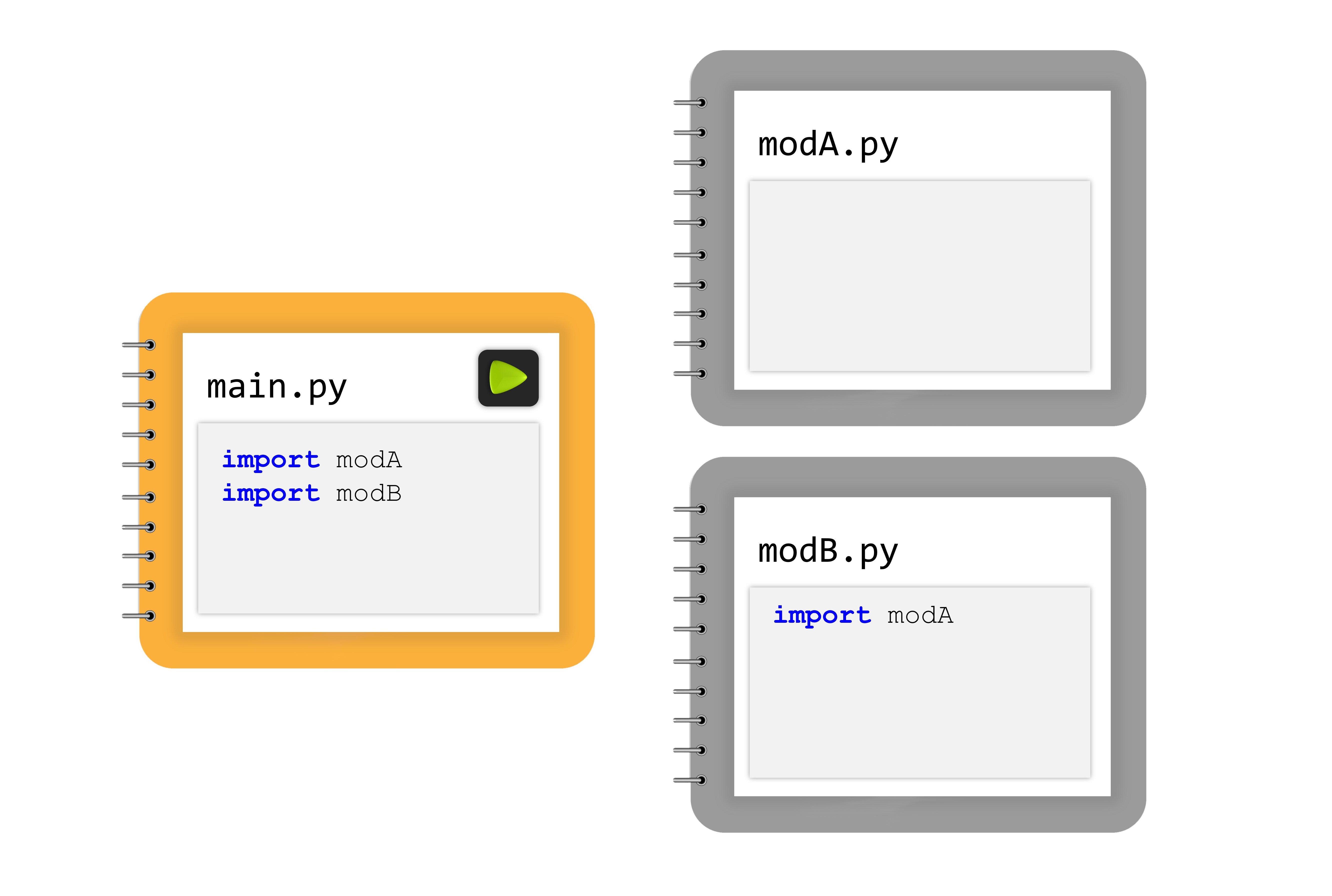
- There is a module named modA.
- There is another module named modB, which contains the instruction
import modA. - There is a main file that includes the instructions
import modAandimport modB.
Even though it may seem like modA would be imported twice (once directly and once through modB), Python ensures that the first import takes place only, and any subsequent imports of the same module are ignored.
Step 5: Understanding name Variable
In addition to importing modules, Python also creates a variable called name. This variable is unique to each source file and is not shared between modules. We will demonstrate how to utilize this variable by making some modifications to the module.
Now, add the following code in module.py, save and run it. You will see the output as shown below.
print("**Module Function**")
print(__name__)Then, in main.py, add the following code save and run it. You will see the output as shown below.
import module
print("This is main function.")To conclude, in Python, there's a special variable called __name__ that behaves differently depending on how you run a file. If you run the file directly, the __name__ variable is set to __main__. On the other hand, if you import the file as a module in another script, the __name__ variable is set to the file's name (without the .py extension).
Step 6: Leveraging the __main__ Variable
You can utilize the __main__ variable to distinguish between running the code as a module or directly. Here's how:
Modify the existing code in module.py as displayed below, save and run it. You will see the output as shown below.
if __name__ == "__main__":
print("Hello! I am a module. Simply run me as a module.")
else:
print("**Module**")This clever technique allows you to place tests within the module to check the functions' correctness. When running the module directly, the tests will be executed, providing a quick way to verify recent changes without affecting the module's behavior when imported.
For a clear view, let's try run the main.py and see what happen. Below is the code contain in main.py, we are not changing anything. Try to run it.
import module
print("This is main function.")To conclude, the __main__ variable provides a powerful way to distinguish between running code as a module or directly. By incorporating tests within the module and running it directly, you can efficiently verify recent changes without impacting the module's functionality when imported. This technique facilitates easy and effective code testing and execution, enhancing the development process.
Step 7: Managing Module Functions and a Variable
Now, assume that we want to keep track of how many times these functions are invoked. And we modify the code in module.py as per shown below. In the shown code, to keep track of how many times these functions are invoked, we use a counter by declaring a variable named counter. So, when the module is imported, the counter should be initialized to zero.
counter = 0
if __name__ == "__main__":
print("Hello! I am a module. Simply run me as a module.")
else:
print("**Module**")However, introducing such a variable is absolutely correct, but may cause important side effects that you must be aware of. Let's try to display the counter value in main.py. Modify the code in main.py as per shown below, save it and run it and observe the output.
import module
print("This is main function.")
print(module.counter)In Python, the main file can access a module's counter variable, which is legal and potentially very useful. However, it's important to consider safety. If you trust your module's users, there's no issue. But if you don't want others to access your personal/private variable, you can use a naming convention to indicate that it's intended for internal use only. You can use a single underscore _ or double underscore __ before the variable name, though it's only a convention and users may choose to disregard it.
Now, let's add two functions to the module for evaluating the sum and product of numbers in a list, while ensuring unnecessary remnants are removed.